C’è il rischio che un algoritmo di Intelligenza Artificiale possa essere stato influenzato da dei bias cognitivi tali da produrre risultati talmente di parte da avere dei pregiudizi razziali? La sfida oggi è quella di sviluppare algoritmi di Intelligenza Aumentata in maniera etica, inclusiva e non discriminante.
Mi rendo conto che il titolo può sembrare un po’ forte, ma l’argomento che voglio trattare è uno di quelli da non sottovalutare: è possibile che un algoritmo di Intelligenza Artificiale, o meglio di Intelligenza Aumentata, risenta di alcuni sostanziali errori di programmazione e bias (Nota 1) tali da rendere un’elaborazione basata su di esso talmente di parte da sfiorare il rischio che sia razzista (Nota 2)?
La risposta, come vedremo in alcuni casi, potrebbe essere affermativa, a seguito di due diverse criticità che vengono proposte di seguito in questo articolo.
Primo problema: ogni algoritmo di Intelligenza Artificiale risente delle scelte fatte sulla scelta dei dati utilizzati durante la fase di machine o deep learning
Ogni Project Leader, Analyst, Architect, Programmatore, Data Scientist ed in generale chiunque intervenga in un progetto di implementazione di un algoritmo di Intelligenza Aumentata compie necessariamente delle scelte. Chi si occupa della definizione della fase di machine o deep learning è chiamato (oltre ad identificare uno o più modelli matematici/statistici) a definire su quali dati, tra tutti quelli a disposizione, egli eseguirà i cicli di training e di test dei modelli.
Queste scelte possono essere intrinsecamente affette dei vizi di fondo: la scelta di quali dati utilizzare può rendere tali dati “parziali” perché le scelte fatte possono dipendere dalla cultura, dagli studi fatti, dall’esperienze del passato, dai pregiudizi, dai valori, dagli stereotipi, dalle credenze che naturalmente compongono l’animo umano (compreso l’animo dei razionalissimi esperti di Data Science). È quello che in termini scientifici viene chiamato bias (Nota 1) ed esso interviene quando la mappa mentale di una persona è condizionata da concetti preesistenti non necessariamente connessi tra loro da legami logici e validi.
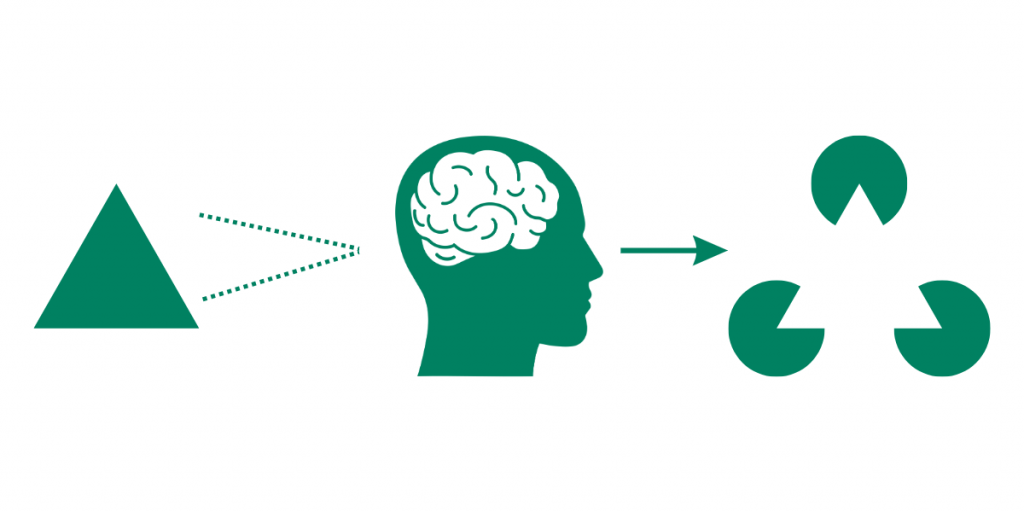
Può accadere che chi implementa progetti di Intelligenza Artificiale possa prendere delle scorciatoie cognitive, certamente in buona fede, ma che possono portare ad intravvedere nei dati dei fenomeni che in realtà non esistono: nell’immagine qui sopra riportata c’è sicuramente un triangolo nero, c’è una persona che sta guardando tre elementi neri, ma non c’è alcun triangolo bianco, anche se a noi sembra di intravvederlo, ma è un’illusione cognitiva.
Non parliamo poi di quando una semplice correlazione tra dati assolutamente scollegati tra di loro viene scambiata per una relazione di causa-effetto: immaginiamo che venga trovata una correlazione tra l’andamento del numero di persone annegate in piscina in Italia ed il numero di automobili vendute in Giappone. Il fatto che i due fenomeni “si muovano statisticamente” in modo similare o correlato, ciò non significa che siano tra di loro in una relazione di causa-effetto.
Da tutto ciò ne deriva il fatto che nell’implementazione di un freddo algoritmo matematico-statistico si può sempre intravvedere anche un “riverbero” più o meno marcato della sensibilità dell’animo umano di chi lo ha implementato o ha semplicemente scelto su quali dati addestrare un Engine di IA. E se l’implementatore fosse mosso da proprie scelte discutibili o avesse dei fini non etici o immorali?
Dare per scontato che tutti questi problemi non esistano e non possano in qualche modo generare delle deformazioni della rappresentazione della realtà prodotta dall’Intelligenza Aumentata è un bias in sé stesso.
Secondo problema: quali sono i limiti endemici che affliggono i dati disponibili al livello mondiale, sui quali eseguiamo i cicli di training dell’Intelligenza Artificiale?
La risposta a questa domanda non è scontata, in particolare quando riflettiamo concretamente sul tema dei dati che realmente sono disponibili su larga scala e a livello mondiale.
Innanzi tutto, dovremmo chiederci:
- Quali sono le nazioni/mercati che oggi producono dati?
- Quali sono i contesti culturali di cui fanno parte queste nazioni?
Ci dovremmo porre queste domande prima di lanciare ogni nuova attività di training di Engine IA che non riguardi fenomeni particolari, ma che abbia un respiro internazionale o si occupi di fenomeni a livello globale.
E se i dati che disponiamo fossero afflitti da un tremendo bias semplicemente perché si tratta di dati parziali?
Rappresentatività dei dati
Per approfondire questo argomento è opportuno dare un’occhiata ad un articolo pubblicato sulla Harward Business Review dal titolo “Which Countries Are Leading the Data Economy?” (Nota 3) scritto da Bhaskar Chakravorti, Ajay Bhalla e Ravi Shankar Chaturvedi, che vi invito a leggere.
In questo articolo viene stillata la classifica delle 30 nazioni al mondo che producono più dati. La classifica tiene conto dei seguenti fattori:
- Volume: quantità assoluta di banda larga consumata da un paese, come indicatore della quantità di dati grezzi generati.
- Utilizzo: numero di utenti attivi su Internet, come indicatore dell’ampiezza dei comportamenti, delle esigenze e dei contesti di utilizzo.
- Accessibilità: apertura istituzionale ai flussi di dati come modo per valutare se i dati generati in un paese consentono una più ampia usabilità e accessibilità da parte di più ricercatori, innovatori e applicazioni di IA.
- Complessità: volume del consumo a banda larga pro capite, come indicatore per la sofisticazione e la complessità dell’attività digitale
Gli autori, nel loro articolo, segnalano che il concetto di “dati” è obiettivamente molto ampio ed è difficile da definire in modo univoco. È interessante capire quale sia l’approccio che i ricercatori hanno proposto per definire il concetto di dato: è noto che, per riconoscere la traccia digitale generata dai sistemi di scambio di dati di tutto il mondo, bisogna coprire ed analizzare una vasta gamma di attività, dall’invio di un messaggio di testo, una email, un post sul social, un SMS, i dati IOT, fino alle transazioni economico-finanziarie.
Per consentire un confronto omogeneo tra dati molto diversi e provenienti da tutto il mondo, hanno proposto di utilizzare la quantificazione della banda larga disponibile pro capite come misura di dell’ampiezza e della complessità dello scambio di dati che avviene in quel luogo del mondo (in qualche modo, imitando l’uso del reddito pro capite come indicatore della prosperità complessiva).
Ed ecco la classifica delle nazioni al mondo che producono più dati, rispetto ai quatto fattori sopra esposti:

Vorrei porre l’attenzione sul fatto che, per i fini del presente articolo, quando si conta il numero delle nazioni al mondo, indirettamente si contano quante diverse aggregazioni “uniche” esistono di individui che tipicamente condividono una lingua, un luogo geografico, una storia, delle tradizioni, un’etnia ed eventualmente un governo: queste aggregazioni sono indirettamente rappresentative di quante diverse Culture (per quanto simili, ma non equivalenti) esistano al mondo.
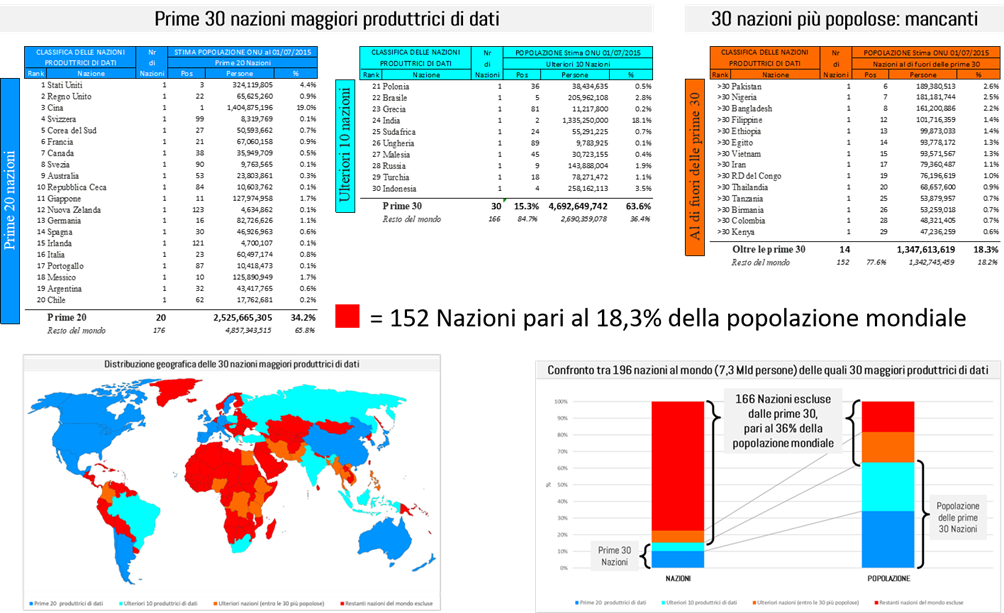
Mi sono quindi posto una domanda molto semplice: queste 30 nazioni quanto rappresentano in termini di numero di individui, rispetto alla popolazione mondiale?
Dall’ultima stima sulla popolazione mondiale redatta dall’ONU con riferimento al 01/07/2015 (Nota 4) si evince quanto segue:
Dei 7,3 miliardi di persone esistenti al mondo sparse in 196 nazioni:
- Le prime 20 nazioni che producono dati hanno una popolazione di 2,5 Miliardi di persone, pari al 34,2% della popolazione totale
- Se si aggiungono le successive 10 nazioni produttrici di dati, si raggiungono i 4,6 miliardi di persone
pertanto, le prime 30 nazioni produttrici di dati al mondo rappresentano il 15,3% delle 196 nazioni, e coprono solo il 63,6% della popolazione totale.
Si deve considerare che la classifica delle 30 nazioni maggiori produttrici di dati non coincide con le 30 nazioni più popolose al mondo: ben 14 nazioni della classifica di quelle più popolose sono escluse dalla classifica delle 30 nazioni produttrici di dati e queste nazioni escluse, da sole, raggiungono il 18,3% della popolazione mondiale.
Considerando che complessivamente l’ONU censisce 196 diverse nazioni al mondo, ne consegue che ci sono ben 166 nazioni che sono praticamente escluse dalla classifica dei 30 maggiori produttori di dati e in esse vive il 36,4% della popolazione mondiale.
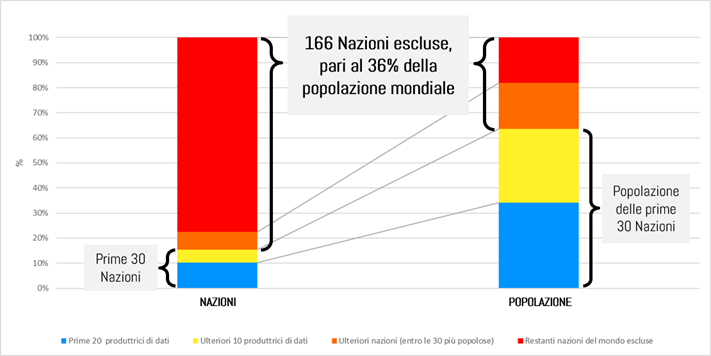
Il tutto poi deve essere letto alla luce del fatto che nelle prime 30 nazioni che producono dati al mondo compaiono anche la Cina e l’India (che complessivamente ammontano al 37,1% della popolazione mondiale), dove è risaputo che la maggior parte della popolazione è ridotta a livelli di povertà tali da non produrre in realtà alcun dato.
Se solo si sottraesse la metà dei cinesi e degli indiani, i quali non dovrebbero comparire nel conteggio delle popolazioni correlate con la produzione di dati, la rappresentatività delle prime 30 scenderebbe dal 63,6 al 45,0% della popolazione mondiale.
Tale rappresentatività parziale delle nazioni/culture correlate alla produzione di dati diventa ancora più marcata se si analizza l’area geografica di provenienza di quei dati
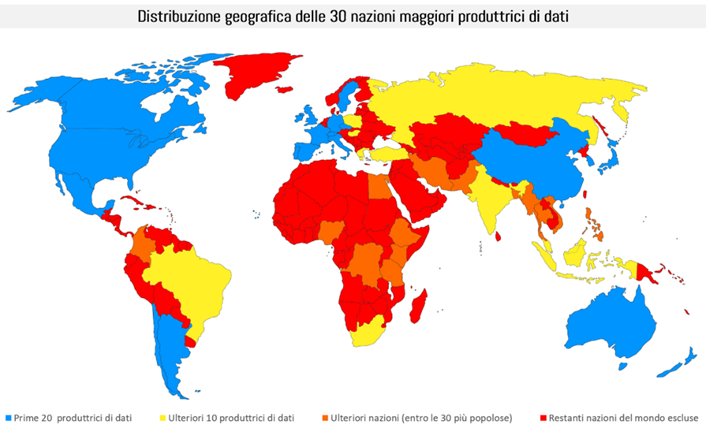
Da questa rappresentazione geografica chiaramente emerge che:
- Ci sono intere aree culturali che non rientrano nella lista delle 30 nazioni che maggiormente producono dati al mondo
- Tali aree culturali (stiamo parlando di ben 166 diverse nazioni) seppur minoritarie per numero di abitanti, o per estensione territoriale, non sono rappresentate termini di dignità e di rappresentatività nelle basi di dati che rappresentano fenomeni globali.
Le 30 nazioni maggiori produttrici di dati ricalcano perfettamente il modello delle nazioni definite WEIRD: Western, Educated, Industrialized Rich and Democratic (occidentali, istruite, industrializzate, ricche e democratiche), che ovviamente non possono essere considerate rappresentative dell’intera umanità. Dobbiamo rassegnarci: i dati oggi a disposizione ed analizzabili con algoritmi di Intelligenza Aumentata, se applicati all’intera popolazione del mondo non sono per ora (purtroppo) rappresentativi.
Conclusione
C’è il concreto rischio che quando gli algoritmi di Intelligenza Aumentata vengono applicati a fenomeni di tipo “macro o globali” i due bias citati in questo intervento si sommino:
- Un primo bias generato dal lato più umano del Data Scientist
- Un secondo bias generato dalla parzialità dei dati generata dal fatto che essi non sono rappresentativi di intere aree culturali del nostro pianeta o non rappresentano determinati gruppi di individui.
Ciò può minare pesantemente l’efficacia delle elaborazioni eseguite tramite un algoritmo di Machine Learning o di Deep Learning, il quale non ha una sua volontà autonoma: si limita solo a studiare i dati che gli vengono forniti.
Non è che l’Intelligenza Aumentata sia “razzista” in sé, ma l’elaborazione generata partendo da dati parziali o affetta da bias dell’implementatore possono trasformare un Engine di IA in un razzista della peggior specie. L’effetto poi è ulteriormente amplificato quando un’elaborazione eseguita su un ridotto set di dati viene estesa in modo arbitrario a livello globale, perdendo quindi di significatività. Ciò può portare in modo fallace anche alla conferma di teorie illogiche, trend inesistenti e fenomeni non reali.
Concludendo, in un progetto di Intelligenza Aumentata, i dati utilizzati per la fase di Machine Learning devono essere sempre “rappresentativi della globalità dei fenomeni”.
Per fare ciò si parte dalla scelta della composizione del team dei Data Scientist, perché già essa stessa è cruciale. Se è vero che è impossibile evitare i bias spesso involontari generati da singoli operatori, è altrettanto vero che tali “bias del singolo” possono essere significativamente mitigati attraverso la creazione di team d’implementazione multiculturali, composti da esperti con percorsi di formazione complementari e con esperienze professionali ed umane le più diversificate possibili.
I dati poi devono rispondere sempre a 4 criteri fondamentali: devono essere rappresentativi di un intero fenomeno, devono essere rilevanti, non devono contenere errori e, cosa assai importante, fin dalla fase di prima analisi, è necessario che tutti quei dati siano validati da persone esperte di settore o di quegli specifici domini di dati.
Solo applicando sempre tutte queste attenzioni si può evitare che un algoritmo di Intelligenza Aumentata generi risultati talmente parziali da rasentare in modo involontario il razzismo.
La sfida oggi è quella di sviluppare algoritmi di Intelligenza Aumentata in maniera etica, inclusiva, non discriminante, ma si parte dalla qualità dei dati e dalla qualità delle persone che li analizzano.
La piena rappresentatività dei dati e la composizione diversificata del team di esperti implementatori sono i principali antidoti a questi rischi, che comunque sono sempre presenti e devono essere tenuti in debita considerazione.
Note e fonti dei dati
Nota 1Bias cognitivo: è un errore sistematico nell’elaborazione delle informazioni utilizzate durante la fase di machine o deep learning di un Engine di IA. Tale errore comporta la generazione di elaborazioni sbagliate, parziali, basate su pregiudizi consci e inconsci o generanti una visione distorta della realtà. Il bias può essere del tutto involontario e di solito lo è e dipende da una scorretta scelta dei dati sui quali eseguire la delicata fase di machine o deep learning. Un sistema basato su un bias dà origine a un machine bias, che può essere poi molto difficile da indentificare una volta che è messo a regime e in funzionamento.
Nota 2Definizione di Razzista dal Vocabolario Treccani: “Razzista è chi predica e pratica il razzismo, inteso sotto il profilo storico come (scrive il Vocabolario Treccani) «ideologia, teoria e prassi politica e sociale fondata sull’arbitrario presupposto dell’esistenza di razze umane biologicamente e storicamente “superiori”, destinate al comando, e di altre “inferiori”, destinate alla sottomissione, e intesa, con discriminazioni e persecuzioni contro di queste, e persino con il genocidio, a conservare la “purezza” e ad assicurare il predominio assoluto della pretesa razza superiore».” http://www.treccani.it/magazine/lingua_italiana/articoli/parole/razzista.html Nel contesto di questo intervento, l’approccio razzista consiste nella non rappresentatività statistica di intere popolazioni all’interno dei database che vengono utilizzati per eseguire cicli di machine learning
Nota 3Which Countries Are Leading the Data Economy? By Bhaskar Chakravorti, Ajay BhallaRavi and Shankar Chaturvedi JANUARY 24, 2019
https://hbr.org/2019/01/which-countries-are-leading-the-data-economy
ONU – World Population Prospects: The 2012 Revision, http://esa.un.org e https://it.wikipedia.org/wiki/Stati_per_popolazione
Nota 5Dettagli su elaborazione propria, basata sulle fonti di dati (Nota 3) e (Nota 4)